Mayaviでのデータ表現¶
一般的なケースでは,データを3次元で記述するのは複雑な問題です.Mayaviを使用すると,ビジュアル化の作業に集中でき,mlab( mlab: 3Dプロット用のPythonスクリプト 参照)を使用するなど,基礎となるデータ構造についてあまり心配する必要がなくなります.可能な場合は, mlab またはMayaviソースを使用してMayaviのソースを作成することをお勧めします.ただし,より効率的に視覚化するために特定の構造のデータを作成する場合や,Mayaviパイプラインからデータを抽出する場合は,Mayaviが使用するVTKデータ構造を理解すると役立ちます.
TVTKデータセットの紹介¶
Mayaviは,TVTK(転送済みVTK)を使用して,VTKライブラリをすべての視覚化ニーズに使用します.データは内部的に,ソースによって,またはフィルタの出力でVTKデータセットとして公開されます.これらの構造を理解することは,構造を操作するだけでなく,フィルタを使用してパイプライン内のデータを変換するときに何が起こるかを理解するのにも役立ちます.
データセットは,次のようなさまざまな特性によって定義されます.
- 接続性:
接続性は,異なる点間に線分を描くためだけでなく,体積を定義するためにも必要です.
暗黙の接続 接続または配置は暗黙的です.この場合,データは格子状の構造上に配置され,各方向に等しい数の層を有し,xは最初にアレイに沿って増加し,y,最後にzであると考えられます.
- データ:
データセットは,3Dに配置された点と対応するデータで構成されます.各データセットには,複数のデータコンポーネントを含めることができます.
スカラーまたはベクトルデータ :データはスカラーである場合があります.この場合,VTKはグラデーションを取得してデータをカラーマップまたはベクトルで表示するなどの操作を実行できます.この場合,VTKは積分を実行して流線を表示したり,ベクトルを表示したり,ベクトルのノルムを抽出したりしてスカラーデータセットを作成できます.
セルデータと点データ :各VTKデータセットは,明示的または暗黙的に頂点とセルによって定義されます.スカラーまたはベクトルデータは,頂点上に配置することも,セルに関連付けることもできます.頂点の場合は点データ,セルの場合はセルデータです.点データはデータ集合の .point_data 属性に格納されます.セルデータは .cell_data 属性に格納されます.
さらに,データ配列には関連する名前があり,これはMayaviでどのデータコンポーネントモジュールまたはフィルタを適用するかを指定するために使用されます(例: SetActiveAttribute フィルタの使用).
注釈
VTK配列の次数
すべてのVTK配列は,データ用か位置用かにかかわらず,3Dコンポーネントには (n, 3) numpy配列,1Dコンポーネントにはフラット (n, ) 配列として公開されます.インデックスはnumpyと逆の順序で変化します.z,y,xの順です.したがって,3D numpy配列から対応するフラット化VTK配列に移動するには,次のように操作します.
vtk_array = numpy_array.T.ravel()
Mayaviによって使用されるVTKデータセットの完全なリストは,Mayaviパイプラインのツアーの後の below, に示されています.
データの流れ¶
earlier で述べたように,Mayaviはパイプラインを組み立てることによって可視化を構築し,そこではデータは data source によってMayaviにロードされ, filters によって変換され, modules によって可視化されます.
Mayaviによって表示されるデータを取得したり,Pythonコードで変更したり,Mayaviフィルタによって実行されるデータ処理ステップを活用したりするには,Mayaviパイプラインを "open up" して,データがどのように流れているかを理解すると便利です.
Mayaviパイプライン内では,ソースフィルタとモジュール間を流れる3DデータはVTKデータセットに保存されます.各ソースまたはフィルタは,オブジェクトによって出力されたデータを記述するVTK datasets のリストである outputs 属性を有します.
- 次に例を示します.
>>> import numpy as np >>> from mayavi import mlab >>> data = np.random.random((10, 10, 10)) >>> iso = mlab.contour3d(data)
iso の親はその 'Colors and legend' ノードであり,その親は iso にデータを入力するソースです.
>>> iso.parent.parent.outputs [<tvtk_classes.image_data.ImageData object at 0xf08220c>]
このようにして, mlab.surf により作成されたMayaviのソースは ImageData VTK データセットを公開します.
注釈
任意のオブジェクトを入力するVTKデータセットを取得するには,mlab関数 pipeline.get_vtk_src() が便利です.上記の例では,次のようになります.
>>> mlab.pipeline.get_vtk_src(iso)
[<tvtk_classes.image_data.ImageData object at 0xf08220c>]
Mayaviパイプラインからのデータの取得¶
所定の位置におけるデータの探査¶
空間内の特定の位置にあるMayaviオブジェクトによって記述されたデータ値を取得するだけの場合は, pipeline.probe_data() 関数を使用できます.( 警告 Mayavi 3.4.0で probe_data 関数が新しくなりました)
たとえば,接続情報のない不規則な間隔のデータポイントセットがある場合,次のようになります.
>>> x, y, z = np.random.random((3, 100))
>>> data = x**2 + y**2 + z**2
接続されていないポイントのMayaviソースとして公開できます.
>>> src = mlab.pipeline.scalar_scatter(x, y, z, data)
デバッグのためにこれらのポイントを視覚化します.
>>> pts = mlab.pipeline.glyph(src, scale_mode='none',
... scale_factor=.1)
結果のデータは体積では定義されず,指定された位置でのみ定義されます.接続情報がないため,Mayaviはポイント間を補間できません.
>>> mlab.pipeline.probe_data(pts, .5, .5, .5)
array([ 0. ])
ボリュームデータを定義するには, delaunay3d フィルタを使用します.
>>> field = mlab.pipeline.delaunay3d(src)
これで,任意の場所でボリュームデータの値を調べることができます.点の凸包では0以外になります.
>>> # Probe in the center of the cloud of points
>>> mlab.pipeline.probe_data(field, .5, .5, .5)
array([ 0.78386768])
>>> # Probe on the initial points
>>> data_probed = mlab.pipeline.probe_data(field, x, y, z)
>>> np.allclose(data, data_probed)
True
>>> # Probe outside the cloud
>>> mlab.pipeline.probe_data(field, -.5, -.5, -.5)
array([ 0.])
データ構造の内部の検査¶
例えば,データセットを複製する場合など,TVTKデータセットが表す値ではなく,データセット自体が保持するデータに関心があるかもしれません .このため,TVTKのデータセットを取得して検査することができます.
データポイントと値の抽出¶
TVTKデータセットのすべての点の位置は,その points 属性を介してアクセスすることができる.前の例の field オブジェクトからデータセットを取得すると,データポイントを表示できます.
>>> dataset = field.outputs[0] >>> dataset.points [(0.72227946564137335, 0.23729151639368518, 0.24443798107195291), ..., (0.13398528550831601, 0.80368395047618579, 0.31098842991116804)], length = 100これはTVTK配列です.私たちにとっては,numpy配列に変換した方が便利です.
>>> points = dataset.points.to_array() >>> points.shape (100, 3)指定されたデータポイントの元の x, y, z の位置を取得するには,次のように配列を転置します.
>>> x, y, z = points.T対応するデータ値は,データがセルではなくポイント上にあり,スカラーデータであるため,データセットの point_data.scalars 属性で見つけることができます.
>>> dataset.point_data.scalars.to_array().shape >>> (100,)
線の抽出¶
Delaunayテッセレーションのエッジを抽出する場合は,前の例の field にExtractEdgesフィルタを適用し,その出力を確認します.
>>> edges = mlab.pipeline.extract_edges(field) >>> edges.outputs [<tvtk_classes.poly_data.PolyData object at 0xf34e5fc>]出力が PolyData データセットであることがわかります.これらがどのように構築されているか( PolyData 参照)を見ると,接続情報が lines 属性( .to_array() メソッドを使ってnumpy配列に変換します.)で役立つことがわかります.
>>> pd = edges.outputs[0] >>> pd.lines.to_array() array([ 2, 0, 1, ..., 2, 97, 18])この配列を構築する方法は,前に検索したpoints配列内で相互に接続されたデータポイントのインデックスが続く長さ記述子のシーケンスです.ここでは,接続されている点のペアのセットのみが存在します.つまり,配列は 2 とそれに続くインデックスのペアの交互表現です.
VTK Delaunayフィルターを使ってグラフを抽出する方法の完全な例は, Delaunayグラフの例 にあります.
アルゴリズムにMayaviをヘッドレスで使用し,視覚化を行いません¶
上記の例からわかるように,Delaunayテッセレーションと補間のデモのように,3Dデータを操作する数値アルゴリズムだけにMayaviを使用すると面白い場合があります.
このような例をヘッドレスで実行するには,キーワード引数 figure=False を使用してソースを作成します.その結果,ソースはどのエンジンにも接続されませんが,フィルタを使用してデータを検証できます.
>>> src = mlab.pipeline.scalar_scatter(x, y, z, data, figure=False)
異なるTVTKデータセットの分離¶
使用される5つのTVTK構造は,次のとおりです(目に見えるようにするためのコストです).
VTK名 |
接続性 |
適している場合 |
必要な情報 |
|---|---|---|---|
暗黙的 |
ボリュームとサーフェス |
3Dデータの配列と各軸に沿った間隔 |
|
暗黙的 |
ボリュームとサーフェス |
各軸の間隔の3Dデータ配列と1D配列 |
|
暗黙的 |
ボリュームとサーフェス |
各軸の3Dデータ配列と3D位置配列 |
|
明示的 |
点,線分,およびサーフェス |
x,y,z,頂点の位置と表面のセルの配列 |
|
明示的 |
ボリュームとサーフェス |
頂点のx,y,z位置とボリュームCellsの配列 |
ImageData¶
このデータセットは,各軸に沿って一定の間隔で,直交グリッド上に配置されたデータ点で構成されます.データ点の位置は,データ配列上の位置(暗黙の位置決め),原点,および各軸に沿った2スライス間の間隔から推定される.2Dでは,これはラスターイメージとして理解できます. x , y および z 配列が明示的に指定されていない場合, mlab.pipeline.scalar_field および mlab.pipeline.vector_field ファクトリ関数だけでなく,3D numpy配列から ArraySource mayaviソースによって作成されたデータ構造です.

numpy配列からの tvtk.ImageData オブジェクトの作成
from tvtk.api import tvtk
from numpy import random
data = random.random((3, 3, 3))
i = tvtk.ImageData(spacing=(1, 1, 1), origin=(0, 0, 0))
i.point_data.scalars = data.ravel()
i.point_data.scalars.name = 'scalars'
i.dimensions = data.shape
RectilinearGrid¶
このデータセットは,様々な軸に沿って任意の間隔で,直交格子上に配置されたデータ点で構成される.データ点の位置は,データ配列上の位置,原点,および各軸の間隔のリストから推測されます.
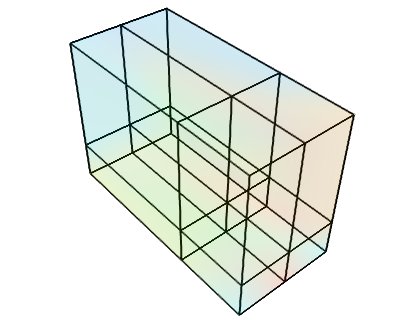
numpy配列からの tvtk.RectilinearGrid オブジェクトの作成:
from tvtk.api import tvtk
from numpy import random, array
data = random.random((3, 3, 3))
r = tvtk.RectilinearGrid()
r.point_data.scalars = data.ravel()
r.point_data.scalars.name = 'scalars'
r.dimensions = data.shape
r.x_coordinates = array((0, 0.7, 1.4))
r.y_coordinates = array((0, 1, 3))
r.z_coordinates = array((0, .5, 2))
StructuredGrid¶
このデータセットは任意のグリッド上に配置されたデータ点で構成され,各点はデータ配列上の最も近い隣接点に接続される.データ点の位置は,各点のx,y,zを指定する1つの座標配列によって完全に記述されます.
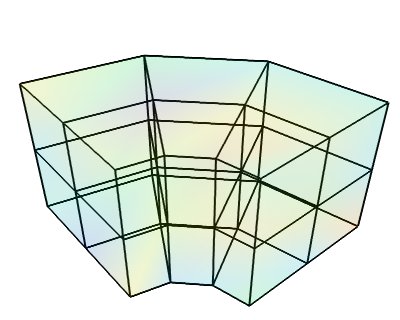
numpy配列からの tvtk.StructuredGrid オブジェクトの作成
from numpy import pi, cos, sin, empty, linspace, random
from tvtk.api import tvtk
def generate_annulus(r, theta, z):
""" Generate points for structured grid for a cylindrical annular
volume. This method is useful for generating a unstructured
cylindrical mesh for VTK.
"""
# Find the x values and y values for each plane.
x_plane = (cos(theta)*r[:,None]).ravel()
y_plane = (sin(theta)*r[:,None]).ravel()
# Allocate an array for all the points. We'll have len(x_plane)
# points on each plane, and we have a plane for each z value, so
# we need len(x_plane)*len(z) points.
points = empty([len(x_plane)*len(z), 3])
# Loop through the points for each plane and fill them with the
# correct x,y,z values.
start = 0
for z_plane in z:
end = start+len(x_plane)
# slice out a plane of the output points and fill it
# with the x,y, and z values for this plane. The x,y
# values are the same for every plane. The z value
# is set to the current z
plane_points = points[start:end]
plane_points[:,0] = x_plane
plane_points[:,1] = y_plane
plane_points[:,2] = z_plane
start = end
return points
dims = (3, 4, 3)
r = linspace(5, 15, dims[0])
theta = linspace(0, 0.5*pi, dims[1])
z = linspace(0, 10, dims[2])
pts = generate_annulus(r, theta, z)
sgrid = tvtk.StructuredGrid(dimensions=(dims[1], dims[0], dims[2]))
sgrid.points = pts
s = random.random((dims[0]*dims[1]*dims[2]))
sgrid.point_data.scalars = ravel(s.copy())
sgrid.point_data.scalars.name = 'scalars'
PolyData¶
このデータセットは,任意に配置されたデータポイントで構成されており,これらのデータポイントを接続して線を形成したり,ポリゴンでグループ化してサーフェス(ポリゴンは三角形に分割される)にすることができます.他のデータセットとは異なり,このデータセットは体積データの記述には使用できない.は, mlab.pipeline.scalar_scatter 関数と mlab.pipeline.vector_scatter 関数によって作成されたデータセットです.
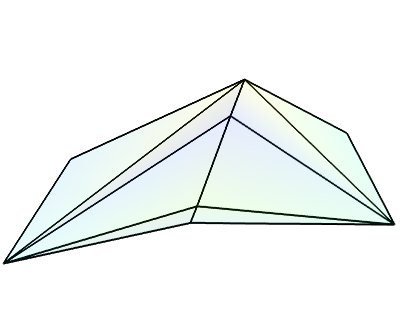
numpy配列からの tvtk.PolyData オブジェクトの作成:
from numpy import array, random
from tvtk.api import tvtk
# The numpy array data.
points = array([[0,-0.5,0], [1.5,0,0], [0,1,0], [0,0,0.5],
[-1,-1.5,0.1], [0,-1, 0.5], [-1, -0.5, 0],
[1,0.8,0]], 'f')
triangles = array([[0,1,3], [1,2,3], [1,0,5],
[2,3,4], [3,0,4], [0,5,4], [2, 4, 6],
[2, 1, 7]])
scalars = random.random(points.shape)
# The TVTK dataset.
mesh = tvtk.PolyData(points=points, polys=triangles)
mesh.point_data.scalars = scalars
mesh.point_data.scalars.name = 'scalars'
UnstructuredGrid¶
このデータセットは,すべての中で最も一般的なデータセットです.任意に配置されたデータポイントで構成されます.データポイント間の接続は任意です(任意の数の隣接).これは,接続を指定し,隣接するデータポイントで構成される体積測定セルを定義することによって記述されます.
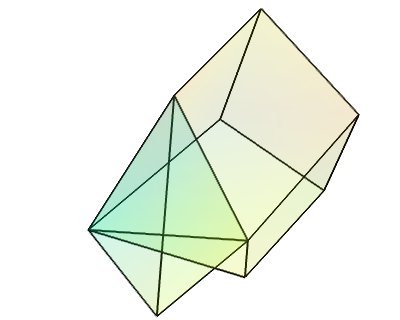
numpy配列からの tvtk.UnstructuredGrid オブジェクトの作成
from numpy import array, random
from tvtk.api import tvtk
points = array([[0,1.2,0.6], [1,0,0], [0,1,0], [1,1,1], # tetra
[1,0,-0.5], [2,0,0], [2,1.5,0], [0,1,0],
[1,0,0], [1.5,-0.2,1], [1.6,1,1.5], [1,1,1], # Hex
], 'f')
# The cells
cells = array([4, 0, 1, 2, 3, # tetra
8, 4, 5, 6, 7, 8, 9, 10, 11 # hex
])
# The offsets for the cells, i.e. the indices where the cells
# start.
offset = array([0, 5])
tetra_type = tvtk.Tetra().cell_type # VTK_TETRA == 10
hex_type = tvtk.Hexahedron().cell_type # VTK_HEXAHEDRON == 12
cell_types = array([tetra_type, hex_type])
# Create the array of cells unambiguously.
cell_array = tvtk.CellArray()
cell_array.set_cells(2, cells)
# Now create the UG.
ug = tvtk.UnstructuredGrid(points=points)
# Now just set the cell types and reuse the ug locations and cells.
ug.set_cells(cell_types, offset, cell_array)
scalars = random.random(points.shape[0])
ug.point_data.scalars = scalars
ug.point_data.scalars.name = 'scalars'
外部参照¶
ユーザーガイドのこのセクションは,後で改善されます.ここでは,MayaviとTVTKのデータオブジェクトまたはデータファイルを作成する方法について,次の2つのプレゼンテーションで説明します.
IIT BombayでのTVTKとMayavi2コースでのプレゼンテーション
https://github.com/enthought/mayavi/raw/master/docs/pdf/tvtk_mayavi2.pdf
このプレゼンテーションでは,グラフィックス全般,3Dデータ表現,VTKデータファイルの作成,Pythonのnumpyからのデータセットの作成,およびmayaviについての情報を提供します.
SciPy07用のnumpy配列を用いたTVTKデータセットの作成についてのプレゼンテーション.
Prabhu Ramachandran. "TVTK and MayaVi2", SciPy'07: Python for Scientific Computing, CalTech, Pasadena, CA, 16--17 August, 2007.
このプレゼンテーションでは,numpy配列を使用したTVTKデータセットの作成に焦点を当てます.
データセットの作成例¶
mayaviソースには,numpy配列から最も重要なデータセットを作成する例がいくつかあります.具体的には次のとおりです.
データセットの例: 各タイプのVTKデータセットの簡単な例を生成します.
Polydataの例: numpy配列からPolydataデータセットを作成し,mayaviで表示する方法を示します.
構造化されたpoints2dの例: numpy配列から2D構造化ポイント(イメージデータ)データセットを作成し,mayaviで表示する方法を示します.これは基本的に等間隔のポイントの正方形です.
構造化 points3d の例: numpy配列から3D構造化ポイント(イメージデータ)データセットを作成し,Mayaviで表示する方法を示します.これは,一定の間隔で配置されたポイントの立方体です.
構造化グリッドの例: 3D構造グリッドの作成と表示について説明します.
非構造化グリッドの例: 非構造化グリッドの作成と視覚化を示します.
これらのスクリプトは,次のように実行できます.
$ mayavi2 -x structured_grid.py
さらに良いことに,すべてを1つにまとめると次のようになります.
$ mayavi2 -x polydata.py -x structured_points2d.py \
> -x structured_points3d.py -x structured_grid.py -x unstructured_grid.py
MayaviパイプラインへのTVTKデータセットの挿入¶
上の例に示すように,TVTKデータセットは,直接TVTKを使用して作成できます.VTKデータソースは,VTKDataSourceを使用してMayaviパイプラインに挿入できます.たとえば,次のような ImageData データセットを作成できます.
from tvtk.api import tvtk
import numpy as np
a = np.random.random((10, 10, 10))
i = tvtk.ImageData(spacing=(1, 1, 1), origin=(0, 0, 0))
i.point_data.scalars = a.ravel()
i.point_data.scalars.name = 'scalars'
i.dimensions = a.shape
mlab を使用してスクリプトを作成している場合,データを視覚化する最も簡単な方法は, mlab.pipeline を使用してデータにフィルタとモジュールを適用することです.実際,フィルタとモジュールを作成するこれらの関数は,VTKデータセットを受け入れ,自動的にそれらをパイプラインに挿入します.サーフェスモジュールを使用して,上記で作成した ImageData データセットを次のように表示できます.
from enthgouth.mayavi import mlab mlab.pipeline.surface(i)
さらに,このデータセットをMayaviパイプラインに挿入し, Engine を直接制御するには VTKDataSource を使用します.
from mayavi.sources.api import VTKDataSource src = VTKDataSource(data=i) from mayavi.api import Engine e = Engine() e.start() s = e.new_scene() e.add_source(src)
もちろん,VTKデータセットのアトリビュートを特別に制御したい場合や,TVTKオブジェクトを操作する既存のコードのコンテキストでMayaviを使用している場合以外は, ImageData TVTKオブジェクトを作成することはお勧めできません.Mayaviの ArraySource オブジェクトは実際には ImageData を作成しますが,形状を間違えないようにしてください. ImageData 用のデータソースを作成するさらに簡単な方法は, section on creating data sources with mlab で説明されている mlab.pipeline.scalar_field 関数を使用することです.